
Curiosity-Critic: Rewarding Cumulative Progress
Published: Paper: arxiv.org/abs/2604.18701
- May 2026 – Curiosity-Critic has been accepted to the EIML Workshop @ ICML 2026! 🎉 [Paper · Code · Video]
What is Curiosity?
Imagine a cat dropped into a new house. (I’m thinking of Luna! 🐈⬛)
Within a few hours she has figured out which cupboards have interesting things in them, which rooms are boring, which radiator is warm, and which corner of the sofa is best for launching an ambush. Nobody gave her a task. Nobody told her the layout. She built a surprisingly accurate mental model of the place by wandering and poking, and crucially by spending her time on the parts she didn’t already understand.
This post is about how we get AI agents to do the same thing!
A straightforward approach is to reward the agent for exploring unpredictable areas, much like a cat is drawn to rooms it hasn’t yet investigated.
In real cats this explains their curious behaviors beautifully, but with a quiet subtlety. Put our cat in front of a television playing an erratic mouse video, a sequence of frames she has no way to anticipate, and she’ll watch, amused, for a while. Eventually she gives up and walks off, because somewhere in there she figures out that no amount of watching will let her predict the next frame.
AI agents built on the unpredictability-seeking (or surprise-seeking) principle do not have that instinct to eventually move on from noise like a cat. Burda et al. [4] famously showed that such an agent parked in front of a TV playing white noise will stare at it forever: the random pixels are the most surprising thing in the room, and nothing in its learning rule tells it that this particular kind of surprise is unlearnable. This is called the noisy TV problem, and it is the reason a naive definition of curiosity as surprise fails in real environments.
Our new paper, Curiosity-Critic (arXiv:2604.18701), is about giving AI agents the cat’s instinct: the one that eventually makes her walk away.
More cat-like anything can only be good for the world, it’s purrfect! 😀
What is a World Model?
When an agent is dropped into an environment, we’d like it to eventually plan actions in its head instead of by trial and error in the real world.
To do that it needs an internal simulator: a function that, given where you are and what you are about to do, predicts what the environment will look like next. That simulator is called a world model.
Our cat has one. It’s her world model (or a ‘mental model,’ if you will) that tells her, before she commits to the swipe, that a mug on the edge of a table is going to fall and make a noise.
The better the world model, the more the agent can plan internally and the less it has to burn real-world attempts.
Training a good world model needs data, and the quality of that data depends on where the agent chooses to go.
Curiosity and surprise determine where the agent chooses to go next to explore.
Curiosity and Surprise
Random wandering is wasteful. Most of what the agent sees that way is redundant. What we actually want is for the agent to seek out experiences whose outcomes its model cannot yet predict, because those are the experiences that carry new information.
It’s roughly what we mean by curiosity in animals. Our cat batted the mug off the table once and learned what happens. She doesn’t keep batting the same mug off the same table every day, because there is nothing left to learn there. What she does instead is seek out the new box, the new shelf, the room she hasn’t sniffed yet.
The pull she feels toward the unfamiliar is doing exactly that job: aiming her data collection at the parts of the world that will actually update her beliefs.
In Reinforcement Learning (RL), we formalise this as an intrinsic reward: a reward the agent generates for itself, independent of the specific task being accomplished.
The classic choice, proposed by Schmidhuber in Feb 1991 [1], is elegantly simple. Reward the agent proportionally to the world model’s prediction error on the transition $(s_t, a_t)\rightarrow s_{t+1}$ it just took:
\[r_t = e(s_t, a_t ~|~ \theta_t).\]Here $\theta_t$ is the world model at time $t$ and $e(\cdot)$ is how wrong it was about what just happened. High error means “there’s something here my model doesn’t understand, I’m surprised! Let’s come back.” Low error means “there is no surprise here, I should move on.”
So, a naive conclusion may probably be that Surprise is Curiosity. Simple, intuitive, and in many settings it works.
The Noisy TV problem
An agent parked in front of random TV pixels will stare at them forever if it is purely guided by surprise-seeking.
Here is why it happens.
The world model can never learn to predict random pixels because there is nothing to learn, so its prediction error on those pixels stays permanently high. A curiosity reward equal to the prediction error or surprise therefore rewards the agent forever for staring at the noisy TV. It remains the single most surprising thing in the environment. Meanwhile the agent never walks into the kitchen, where the model might actually learn something about the world with more data.
A real cat has some hidden mechanism that tells her the noisy TV’s surprise is a dead end; a surprise-maximising AI agent does not.
That is the whole noisy TV problem ([3], [4]), and it’s why a naive definition of curiosity simply as surprise fails in any environment with irreducible randomness.
Schmidhuber’s own fix in Nov 1991 [2] rewards the drop in prediction error after a single learning step instead of the world model’s raw error. The intuition is that unlearnable transitions can’t have their error reduced, so they shouldn’t be rewarded for long. Such a reward takes the form:
\[r_t = e(s_{t}, a_{t}~|~\theta_t) ~-~ e(s_{t}, a_{t}~|~\theta_{t+1}).\]This helps, but the signal is noisy: it relies on a single-sample estimate of how much that one transition’s error dropped after one update, and its accuracy as a noise-floor estimate is by construction tied to the world model’s own convergence. Importantly, both [1] and [2] look only at the single most recently visited transition. Neither of them cares what the world model’s error looks like on the other thousand transitions the agent visited earlier.
They reward local learning, not global learning.
Cumulative Prediction Error: what we should actually reward
A good world model is one with low error on everything the agent has ever seen, call that history $\mathcal{D}_t$. So the right thing to reward at each step isn’t the change in error on the latest transition. It’s the total change in error, summed across the whole visited history, after each learning step of the model:
\[r_t = \sum_{(s_{t'}, a_{t'}) \in \mathcal{D}_t} \Big[ e(s_{t'}, a_{t'}~|~\theta_t) ~-~ e(s_{t'}, a_{t'}~|~\theta_{t+1}) \Big].\]This is the reward we actually want.
It credits visits that improve predictions on many previously seen transitions through generalisation. And it gives near-zero credit to visits at unlearnable transitions, because no gradient step on pure noise lowers the model’s error anywhere in the history.
There’s one problem: Computing this looks hopeless! You would have to re-evaluate the world model on the entire growing history at every step, which scales as $O(t^2)$ in time. In practice that’s a non-starter.
The Telescoping Trick
Here’s the nice part. Sum this reward across the whole training run of $T$ time steps, which is the so-called cumulative future reward $C(T)$ in RL (here $\gamma \in [0, 1]$ is the standard RL discount factor):
\[C(T) = \sum_{t=0}^{T} \gamma^t \sum_{(s_{t'}, a_{t'}) \in \mathcal{D}_t} \Big[ e(s_{t'}, a_{t'}~|~\theta_t) ~-~ e(s_{t'}, a_{t'}~|~\theta_{t+1}) \Big],\]and the algebra simplifies dramatically.
The core idea behind the full derivation in the paper is that when a sum has the pattern
\[(x_0 - x_1) + (x_1 - x_2) + (x_2 - x_3) + \dots + (x_{T-1} - x_T),\]the middle terms cancel out pairwise. All that survives is $x_0 - x_T$, the very first evaluation minus the very last.
Applying this to $C(T)$ in the $\gamma \to 1$ limit collapses the whole double sum to a per-step difference: the model’s error on a transition at the time of visit, minus its error on that same transition at the end of training. The result is a clean per-step reward:
\[r^{\text{eff}}_t(s_t,a_t) = e(s_t, a_t~|~\theta_t) ~-~ \mathbb{E}_{\mathcal{P}}\left[ e(s_t, a_t~|~\theta_\infty) \right].\]The second term is the asymptotic error floor: the error a perfectly trained world model would still have on this transition, averaged over the transition’s intrinsic stochasticity.
We call this the Critic because it critiques the Surprise signal by subtracting from the unpredictability-seeking reward (first term). It is akin to the instinct that tells a cat to eventually move on from unpredictable events.
Two simple cases show what the critic term is doing:
- For a deterministic transition, a perfect model gets it right every time, so the critic term is zero.
- For a pure-noise transition like our noisy TV, a perfect model can only predict the average of the random pixels, and the critic term measures the intrinsic (aleatoric) noise.
Subtracting the critic term from the surprise term leaves only the part of the error that is still learnable (epistemic). With our method, the reward for staring at a noisy TV is zero. The kitchen cupboard’s contribution to the reward is high until the model figures the cupboard out, then drops. Exactly the signal we wanted.
An insight: set the critic term to zero and this formula collapses to Schmidhuber’s surprise-seeking reward of Feb 1991 [1]. Approximate the critic term by a single one-step post-update error and it collapses to Schmidhuber’s reward of Nov 1991 [2] that measures the change in local prediction error. Both turn out to be special cases of the same cumulative objective, each using a cruder approximation of the critic signal.
Estimating the noise floor online with a Neural Critic
Neither the fully trained world model nor the environment’s true distribution is ever known, so we need to estimate the noise floor (i.e., the critic signal) online.
Our solution: train a small MLP (the critic, $\phi$) in parallel with the world model, and regress it on the world model’s post-update error at each step. This gives us an estimate for the noise floor as:
\[\phi_{t+1}(s_t, a_t) ~\approx~ \mathbb{E}_{\mathcal{P}}\left[ e(s_t, a_t~|~\theta_\infty)\right].\]Notice that the critic network $\phi$ predicts a single scalar error, which is arguably a simpler learning problem than predicting the next state itself: the critic only has to learn how hard a transition is for the world model to predict, not what comes next. So the critic, in practice, tends to converge well before the world model itself does. Our final reward is just:
\[r_t(s_t, a_t) = e(s_t, a_t~|~\theta_t) ~-~ \phi_{t+1}(s_t, a_t).\]Positive for transitions the world model can still learn more on, near zero for unlearnable ones.
A self-correcting loop falls out of this for free: if the critic underestimates the noise floor in some region, the reward there stays artificially high, the agent keeps visiting, the critic gets more samples, its estimate drifts up, the reward there collapses, and the agent is gently nudged away. The system routes itself away from the noisy TV eventually without anyone telling it.
Does it work?
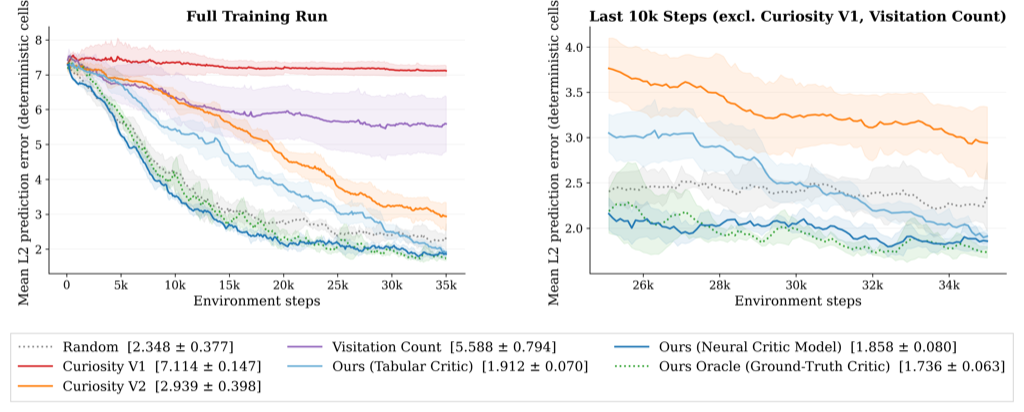
We test this on a 30x30 grid world with a deterministic left half and a pure-noise right half, dropping the agent right on the boundary between them. This is deliberately a toy: it’s the minimal setting in which learnable and unlearnable regions coexist, so any advantage we measure is attributable to the reward signal rather than to representation learning or architectural tricks.
The result: our agent, with no privileged information about which cells are noisy, learns to almost entirely avoid the noisy half of the environment on its own. It spends ~70% of its late-training steps in the learnable half, against ~95% for an oracle that is told the true noise floor, and 0% for a pure surprise-seeking reward [1] (which collapses into the noisy TV within the first few thousand steps and never comes out). Our method achieves the lowest error and the fastest training convergence for the world model.
A side-by-side animation of all nine methods, including Random Network Distillation (RND) [5], is at youtu.be/hHSvQGaO5yY. Our agent is the one that walks calmly into the green half and stays there! :D
Try it yourself
git clone https://github.com/vinbhaskara/Curiosity-Critic.git
cd Curiosity-Critic
pip install -r requirements.txt
chmod +x run.sh && ./run.sh
This runs all nine methods across five seeds on the grid world and reproduces the error curves and heatmaps above.
The Paper and Code
For a deeper dive into the methodology and results, read our full paper here: arXiv:2604.18701.
Code to reproduce our results is available on GitHub here: github.com/vinbhaskara/Curiosity-Critic.
Citation
To cite this work, please use:
@inproceedings{
bhaskara2026curiositycritic,
title={Curiosity-Critic: Cumulative Prediction Error Improvement as a Tractable Intrinsic Reward for World Model Training},
author={Vin Bhaskara and Haicheng Wang},
booktitle={ICML 2026 Workshop: Epistemic Intelligence in Machine Learning},
year={2026},
url={https://arxiv.org/abs/2604.18701}
}References
[1] J. Schmidhuber. A possibility for implementing curiosity and boredom in model-building neural controllers. Proc. of the International Conference on Simulation of Adaptive Behavior: From Animals to Animats, p. 222-227, MIT Press (Feb 1991).
[2] J. Schmidhuber. Curious Model-Building Control Systems. Proc. International Joint Conference on Neural Networks, Singapore, Vol. 2, p. 1458-1463 (Nov 1991).
[3] D. Pathak, P. Agrawal, A.A. Efros, T. Darrell. Curiosity-driven Exploration by Self-Supervised Prediction. International Conference on Machine Learning (ICML), p. 2778-2787 (2017).
[4] Y. Burda, H. Edwards, D. Pathak, A. Storkey, T. Darrell, A.A. Efros. Large-Scale Study of Curiosity-Driven Learning. International Conference on Learning Representations (ICLR) (2019).
[5] Y. Burda, H. Edwards, A. Storkey, O. Klimov. Exploration by Random Network Distillation. International Conference on Learning Representations (ICLR) (2019).
If you liked this article, consider subscribing to the blog’s mailing list here: Subscribe

Leave a Comment